机器学习三要素
机器学习(本文主要指的是监督学习)的最主要目标,是要让算法的最终结果跟实际真实值之间的损失函数值最小:
$$argmin_{f \in \cal F} \frac{1}{N} \sum_{i=1}^{N}L(y_i, f(x_i)) + \lambda J(f)$$
对这个公式而言,主要可以将机器学习过程分解成三个部分:
模型(model)
模型指的是$\cal F$,一般而言有CNN/SVM/LDA等等,我们的目标是要通过调整参数,从模型的参数空间中找出一个参数组合,使得在这个参数组合下,模型的损失函数值最小。
首先需要区分一个概念,$\cal F$和$f$的关系与区别。$\cal F$指的是一个概念模型,比如SVM指的是支持向量机,那么在这个模型概念下,不一样的参数组合,就会生成不一样的具体模型,比如在支持向量机中,选择不同的核函数可以生成不同的具体的SVM模型($f$)。
其实,$\cal F$是一个参数空间,是决策函数(也就是具体模型)$f$的一个值域空间。我们的目标是找出一个具体模型(知道这个具体函数的参数),使得损失函数最小化。
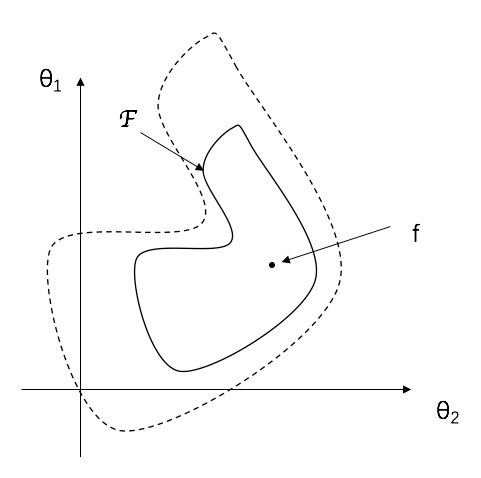
以上这幅图,仅仅针对一个二维参数空间而言,对于不同的模型$\cal F$,有着不同的参数空间,比如上图实线所包围的部分,就指代了模型$\cal F$的能取值到的值域。选择不同的参数,在当前所选择的概念模型下,能生成不同的具体模型。当然,具体模型中,参数肯定不止两个,那么这个参数空间就是一个高维的参数空间。
对于不同的模型($\cal F$),有着不同的表达能力,比如上图中虚线部分所代表的模型,表达能力大于实线部分,因为它能取到的参数空间完全包含了实线部分。比如四层卷积神经网络的表达能力大于三层。
但是否表达能力越好的模型越好呢?这其实是一个权衡的问题,表达能力越好,也代表着可能这个模型的代价更高,所以我们要选择适合的模型而不是最好的模型,在有限的计算资源下,选出表达能力最佳的模型。
那,是否可以把不同的概念模型($\cal F$)也当做一个参数维度传入参数空间呢?其实也是可以的,只不过因为计算资源有限,我们要去遍历不同的概念模型需要付出较大的代价,往往会选择某个概念模型,而不会都尝试一下。
策略(strategy)
损失函数
策略的一部分是损失函数,也称为代价函数。也就是$L(y_i, f(x_i))$。
我们首先要了解$y_i$和$f(x_i)$之间的关系是什么。总体而言,机器学习的目标就是要能根据输入,得到一个尽量接近事实的输出值。比如通过西瓜的外表,来预测西瓜是否是一个好瓜。
那么,在我们训练出模型之后,我们要在测试集上,来测试我们的模型的效果是否满意,就需要比对训练集对于测试集上数据(这些数据有已经得到的输入和输出对$(x_i, y_i)$,我们可以认为测试集的$y_i$是一个ground truth,也就是标准答案)的输出($f(x_i)$)和真实值($y_i$)之间的差距。于是乎,我们的损失函数,就是用来做这件事情的。损失函数越小,就代表我们的模型拟合的越好。
一般而言,常用的损失函数有:(1)0-1损失函数(0-1 loss function),(2)平方损失函数(quadratic loss function),(3)绝对损失函数(absolute loss function),(4)对数损失函数(logarithmic loss function)。
风险函数
由于损失函数度量的是某一次预测结果的好坏,我们希望衡量一下平均情况,这个平均情况也被称为经验风险(empirical risk)或者说经验损失(empirical loss)。
$$R_{emp}(f) = \frac{1}{N} \sum_{i=1}^{N}L(y_i, f(x_i))$$
除了经验损失以外,策略还包含结构风险(structural risk)。
因为样本容量较小时,容易产生过拟合的现象,需要用结构风险来度量过拟合。于是结构风险最小化(structural risk minimization SRM)也就成了策略的目标之一。结构风险的定义如下:
$$R_{emp}(f) = \frac{1}{N} \sum_{i=1}^{N}L(y_i, f(x_i)) + \lambda J(f)$$
其中$J(f)$表达了模型的复杂度。$\lambda J(f)$是整个结构风险的一个罚项(penalty term),因为模型越简单,复杂度就越小,过拟合的风险就越小,故而通过模型复杂度来衡量过拟合的风险。
算法(algorithm)
算法,指的就是如何找出最佳参数组合,求解最优$f$的过程,也就是可以理解为调参的过程。算法的目标就是找到全局最优解,以及求解过程的高效率和低开销。